
![]() Optimal Routing Strategies for Interception in USSV-Intruder System
Optimal Routing Strategies for Interception in USSV-Intruder System
PI: Dr. Nikhil Chopra and Prof. S.K. Gupta
The problem where an Unmanned Sea Surface Vehicle (USSV) is protected from an Intruder vessel in unknown environments by designing online strategies for intercepting are studied. It is assumed that the USSV does not have knowledge of the intruder’s future action, value function to be optimized, and the environment parameters. The mission was to assign an optimal trajectory for the USSV so that it can intercept the Intruder in minimum time. The focus of the project was on designing online control strategies for the USSV so that it would be able to intercept the Intruder independent of the time-varying control policies, and in unknown environments.
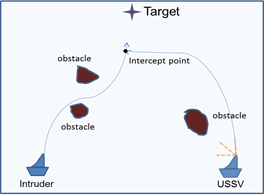
The Interception Problem
The original problem was considerably complicated to solve due to the continuous nature of the state, and the action space. To simplify the problem, it was assumed that the state space is two dimensional, and that the USSV/Intruder moved with constant speed. The desired action was then the optimal moving direction at every state of the two dimensional grid. The absence of sensor uncertainty was also assumed in the proposed formulation for the sake of simplicity. We also adopted a discrete time model for the overall system. The action choices (directions to move) at every state were chosen to be finite. Hence, the system was simplified to a finite state, finite action, discrete time problem.
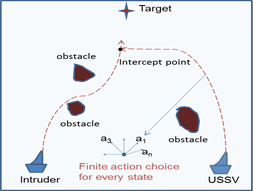
The Simplified Interception Problem
After a critical survey on different methods, Approximate Dynamic Programming (ADP) was selected to obtain the optimal policy for the USSV system. The ADP methodology was chosen as it can be utilized for solving complex optimal control without knowledge of the precise system dynamics.
It was assumed that the underlying dynamical system can be approximated as a Markov Decision Process (MDP). The transition probability matrix for the USSV system is usually not known precisely. In this situation, the Q function is utilized instead of the value function for deciding the optimal control policy. The ADP algorithm was applied to the USSV system. It was able to approximate the real Q function, and update the policy online.
In the USSV-Intruder system, the goal of USSV is to minimize the time to intercept the Intruder, and the goal of Intruder is to maximize the time to meet the USSV. We simulated selected samples and compared the resulting reward to decide the best action and update the policy. While initial results in this direction appear promising, the primary drawback is that information about the methodology for choosing the best action is known by both players, and hence a distributed solution to the Fictitious Play problem needs to be developed.
