
![]() Simulation Based Learning for Optimal Semi-Autonomous Operation of USSV Teams
Simulation Based Learning for Optimal Semi-Autonomous Operation of USSV Teams
PIs: Prof. Nikhil Chopra and Prof. S K Gupta
Complex naval missions often require deployment of teams of Unmanned Sea Surface Vehicles (USSVs) and human operators in unknown environments. These missions may possibly consist of many heterogeneous tasks. An important aspect of the mission planning is the task assignment process for the USSVs. Due to the dynamic nature of the environment, tasks may continuously vary depending upon the state of the environment. Thus, mission planning is not an off-line process but on-line in nature and needs to be performed continually throughout the mission to update the task assignments based on the events in the environment.
Another key decision that needs to be made as a part of the mission planning is to decide whether to operate a particular USSV autonomously or in a tele-operated mode. Depending on the environment encountered during a mission, sections of the workspace may be ideal for autonomous operation and portions of it may require tele-operating the USSVs. Hence, in the near foreseeable future USSV team operations are expected to be semiautonomous in nature. In order to achieve optimal semi-autonomous operation, several important factors need to be considered. The first important question is how many operators are needed for optimizing the value function for a given mission. The value function for a mission will need to account for both the mission cost and the mission performance. Utilizing a small number of operators may give lead to lower mission cost but also poor mission performance implying poor mission value. On the other hand using too many operators may
lead to high cost and only marginally improve the mission performance, thereby again resulting in a low mission value.
Classical optimal control methods such as dynamic programming can be used to optimize the value function if the control designer has good knowledge of the overall system and environment parameters. However, this approach in not viable for controlling the USSV system due to the stochastic nature of the problem and the additional consideration that the number of iterations grow exponentially in the number of states and actions. Hence, learning and stochastic optimization methods have to be deployed to solve the optimal control policy problem for the semi-autonomous USSVs. It is to be noted that to test which policy is optimal, the designer faces several constraints such as the fact that only a single policy can be studied at a particular time on the simulator or the real system. Furthermore, by learning the behavior of one policy, it is not possible to obtain information about other policies if no information is available for the system under consideration. If here is no information about the system, then search methods such as genetic algorithms, simulated annealing, etc. have to be utilized. On the other hand, if structural information is available, then methods such as Markov decision problems, reinforcement learning, and identification and adaptive control can be used to learn the optimal policy.
In this work, we focus on reinforcement learning to obtain the optimal policy for the semiautonomous USSV systems. Depending on whether the policy space is continuous or discrete, methods such as performance gradient or policy iteration can be adopted. However, assuming that underlying process is Markov, these methods rely on knowing the relative cost in sample paths and the transition probability matrices. These parameters are expected to be largely unknown in the USSV system and hence simulation data will be used to estimate these parameters using reinforcement learning methods. The relative costs and the transition probability matrices, or atleast some of them can be pre-calculated using extensive offline simulations with human operators. Subsequently, it is likely that in the real time scenario, these estimates together with the learning methods will be able to yield the optimal policies for the semi-autonomous USSV system.
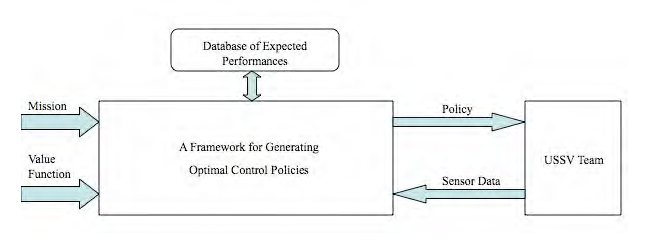
A reinforcement learning framework for semi-autonomous control
